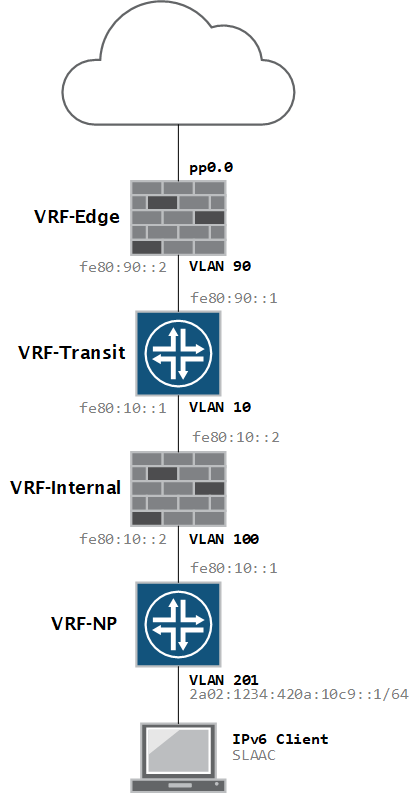
Two more weeks left to take the JNCIP-SEC exam, or I will lose my JNCIS-SEC credentials. I have a fully loaded SRX320 cluster (with advanced feature licenses) and a vSRX in place so I need to lab up quickly. First feature on the list is Juniper Enhanced Web filtering.
Before you begin the configuration, make sure you meet the following prerequisites:
- The device has a valid wf_key_websense_ewf license
- The egress interface has internet connectivity
- The device has working name-servers defined
- If you are enabling the feature on a virtual router, be sure to define the VR under
[edit security utm feature-profile web-filtering]
To activate the Juniper Enhanced Web Filtering feature, enter the following command:
[edit security utm feature-profile web-filtering] root@NP-vSRX# show type juniper-enhanced;
Next, enable the UTM feature profile for Juniper Enhanced Web Filtering and configure the Juniper-managed Websense server URL.
[edit security utm feature-profile web-filtering]
root@NP-vSRX# show
juniper-enhanced {
server {
host rp.cloud.threatseeker.com;
port 80;
}
}
Before we configure the Websense categories, we should define custom whitelists and blacklists, which can be used to overrule unexpected results from the automated Websense categorization.
Under the UTM custom-objects, we’ll create an URL pattern for one of our favorite networking-related forums and for a blacklisted adult site. These are then addded to custom black/whitelist categories.
[edit security utm custom-objects]
root@NP-vSRX# show
url-pattern {
URL-networking-forumsdotcom {
value [ http://networking-forums.com 64.90.58.116 ];
}
URL-sexdotcom {
value [ sex.com 206.125.164.82 ];
}
}
custom-url-category {
EWF-Blacklist {
value URL-sexdotcom;
}
EWF-Whitelist {
value URL-networking-forumsdotcom;
}
}
Our two custom URL categories are added under the global web-filtering configuration.
[edit security utm feature-profile web-filtering] root@NP-vSRX# show url-whitelist EWF-Whitelist; url-blacklist EWF-Blacklist;
As for the Enhanced Web-filtering example, I’ll create one profile for standard internet access called “WF-DefaultInternetAccess”. Adult content and malicious URLs/IP addresses will be blocked by default and some ‘undesirable’ categories will be allowed, yet a security event will be logged. The default action will be set to “permit”.
[edit security utm feature-profile web-filtering juniper-enhanced]
root@NP-vSRX# show
cache;
server {
host rp.cloud.threatseeker.com;
port 80;
}
profile WF-DefaultInternetAccess {
category {
Enhanced_Adult_Content {
action block;
}
Enhanced_Adult_Material {
action block;
}
Enhanced_Advanced_Malware_Command_and_Control {
action block;
}
Enhanced_Advanced_Malware_Payloads {
action block;
}
Enhanced_Bot_Networks {
action block;
}
Enhanced_Dynamic_DNS {
action block;
}
Enhanced_Emerging_Exploits {
action block;
}
Enhanced_Keyloggers {
action block;
}
Enhanced_Malicious_Embedded_Link {
action block;
}
Enhanced_Malicious_Embedded_iFrame {
action block;
}
Enhanced_Malicious_Web_Sites {
action block;
}
Enhanced_Mobile_Malware {
action block;
}
Enhanced_Parked_Domain {
action block;
}
Enhanced_Phishing_and_Other_Frauds {
action block;
}
Enhanced_Proxy_Avoidance {
action block;
}
Enhanced_Spyware {
action block;
}
Enhanced_Abused_Drugs {
action log-and-permit;
}
Enhanced_Alcohol_and_Tobacco {
action log-and-permit;
}
Enhanced_Drugs {
action log-and-permit;
}
Enhanced_Gambling {
action log-and-permit;
}
Enhanced_Games {
action log-and-permit;
}
Enhanced_Hacking {
action log-and-permit;
}
Enhanced_Illegal_or_Questionable {
action log-and-permit;
}
Enhanced_Nudity {
action log-and-permit;
}
Enhanced_Racism_and_Hate {
action log-and-permit;
}
Enhanced_Sex {
action log-and-permit;
}
}
default permit;
fallback-settings {
default log-and-permit;
server-connectivity block;
timeout block;
too-many-requests block;
}
}
In case a URL does not have a category assigned but only a Web Reputation Score (WBRS) we can define an action based on that score.
Note – the scores are weighted as follows:
- 100-90–Site is considered very safe.
- 80-89–Site is considered moderately safe.
- 70-79–Site is considered fairly safe.
- 60-69–Site is considered suspicious.
- 0-59–Site is considered harmful.
[edit security utm feature-profile web-filtering juniper-enhanced profile WF-DefaultInternetAccess site-reputation-action] root@NP-vSRX# show very-safe permit; moderately-safe permit; fairly-safe log-and-permit; suspicious quarantine; harmful block;
For some special cases, in which the device might not be able to process the HTTP request, we can define fallback options. This basically equates to a fail-open/fail-closed decision.
[edit security utm feature-profile web-filtering juniper-enhanced profile WF-DefaultInternetAccess fallback-settings] root@NP-vSRX# show default log-and-permit; server-connectivity block; timeout block; too-many-requests block;
With most pieces in place, the full web-filtering profile looks like this:
[edit security utm feature-profile]
root@NP-vSRX# show
web-filtering {
url-whitelist EWF-Whitelist;
url-blacklist EWF-Blacklist;
type juniper-enhanced;
juniper-enhanced {
cache;
server {
host rp.cloud.threatseeker.com;
port 80;
}
profile WF-DefaultInternetAccess {
category {
Enhanced_Adult_Content {
action block;
}
Enhanced_Adult_Material {
action block;
}
Enhanced_Advanced_Malware_Command_and_Control {
action block;
}
Enhanced_Advanced_Malware_Payloads {
action block;
}
Enhanced_Bot_Networks {
action block;
}
Enhanced_Dynamic_DNS {
action block;
}
Enhanced_Emerging_Exploits {
action block;
}
Enhanced_Keyloggers {
action block;
}
Enhanced_Malicious_Embedded_Link {
action block;
}
Enhanced_Malicious_Embedded_iFrame {
action block;
}
Enhanced_Malicious_Web_Sites {
action block;
}
Enhanced_Mobile_Malware {
action block;
}
Enhanced_Parked_Domain {
action block;
}
Enhanced_Phishing_and_Other_Frauds {
action block;
}
Enhanced_Proxy_Avoidance {
action block;
}
Enhanced_Spyware {
action block;
}
Enhanced_Abused_Drugs {
action log-and-permit;
}
Enhanced_Alcohol_and_Tobacco {
action log-and-permit;
}
Enhanced_Drugs {
action log-and-permit;
}
Enhanced_Gambling {
action log-and-permit;
}
Enhanced_Games {
action log-and-permit;
}
Enhanced_Hacking {
action log-and-permit;
}
Enhanced_Illegal_or_Questionable {
action log-and-permit;
}
Enhanced_Nudity {
action log-and-permit;
}
Enhanced_Racism_and_Hate {
action log-and-permit;
}
Enhanced_Sex {
action log-and-permit;
}
}
site-reputation-action {
very-safe permit;
moderately-safe permit;
fairly-safe log-and-permit;
suspicious quarantine;
harmful block;
}
default permit;
fallback-settings {
default log-and-permit;
server-connectivity block;
timeout block;
too-many-requests block;
}
}
}
}
Next, we need configure a new UTM policy which includes the Enhanced Web Filtering feature. This can be combined with other UTM features such as Sophos anti-virus or content filtering.
[edit security utm] root@NP-vSRX# set utm-policy UTM-DefaultInternetAccess web-filtering http-profile WF-DefaultInternetAccess
The last step is to attach the UTM profile to a security policy by configuring the application-services action.
[edit security policies from-zone internal-np to-zone internal-transit policy FW-Internal-PermitAll]
root@NP-vSRX# show
match {
source-address any;
destination-address any;
application any;
}
then {
permit {
application-services {
utm-policy UTM-DefaultInternetAccess;
}
}
}
Configuring logging
To make webfilter troubleshooting easier, configure the following syslog files, or alternatively send them to a syslog server.
[edit system syslog]
root@NP-vSRX# show
file blocked-sites {
any any;
match WEBFILTER_URL_BLOCKED;
}
file allowed-sites {
any any;
match WEBFILTER_URL_PERMITTED;
}
Testing
Testing the custom blacklist by browsing to sex.com – HTTPS session was broken (based on destination IP) and the browser returned an error.
Oct 13 14:21:14 NP-vSRX RT_UTM: WEBFILTER_URL_BLOCKED: WebFilter: ACTION="URL Blocked" 10.255.1.13(50278)->206.125.164.82(443) CATEGORY="EWF-Blacklist" REASON="BY_BLACK_LIST" PROFILE="WF-DefaultInternetAccess" URL=206.125.164.82 OBJ=/ username N/A roles N/A
Next, we test the URL in the whitelist (which was actually be blocked by Websense). Networking-forums loads fine now and we have this in the log:
Oct 13 14:23:43 NP-vSRX RT_UTM: WEBFILTER_URL_PERMITTED: WebFilter: ACTION="URL Permitted" 10.255.1.13(50303)->64.90.58.116(443) CATEGORY="EWF-Whitelist" REASON="BY_WHITE_LIST" PROFILE="WF-DefaultInternetAccess" URL=64.90.58.116 OBJ=/ username N/A roles N/A
As a last test, we initiate an HTTP session to http://www.penthouse.com
In the browser, we get the following message:
Juniper Networks Firewall has blocked the URL: 10.255.1.13(62175)->64.59.126.214(80) www.penthouse.com/ CATEGORY: Enhanced_Adult_Content REASON: BY_PRE_DEFINED
And in the syslog file, it looks like this:
Oct 13 14:33:29 NP-vSRX RT_UTM: WEBFILTER_URL_BLOCKED: WebFilter: ACTION="URL Blocked" 10.255.1.13(62175)->64.59.126.214(80) CATEGORY="Enhanced_Adult_Content" REASON="BY_PRE_DEFINED" PROFILE="WF-DefaultInternetAccess" URL=www.penthouse.com OBJ=/ username N/A roles N/A
Verification Commands
To check connectivity between your SRX and the Juniper Websense server:
root@NP-vSRX> show security utm web-filtering status
UTM web-filtering status:
Server status: Juniper Enhanced using Websense server UP
Web-filtering statistics – this is useful when the service is not working as expected.
root@NP-vSRX> show security utm web-filtering statistics
UTM web-filtering statistics:
Total requests: 17086
white list hit: 20
Black list hit: 20
No license permit: 0
Queries to server: 6472
Server reply permit: 1868
Server reply block: 9
Server reply quarantine: 0
Server reply quarantine block: 0
Server reply quarantine permit: 0
Custom category permit: 0
Custom category block: 0
Custom category quarantine: 0
Custom category qurantine block: 0
Custom category quarantine permit: 0
Site reputation permit: 10597
Site reputation block: 2495
Site reputation quarantine: 49
Site reputation quarantine block: 0
Site reputation quarantine permit: 1170
Site reputation by Category 0
Site reputation by Global 14311
Cache hit permit: 847
Cache hit block: 11
Cache hit quarantine: 0
Cache hit quarantine block: 0
Cache hit quarantine permit: 0
Safe-search redirect: 0
Web-filtering sessions in total: 128000
Web-filtering sessions in use: 2
Fallback: log-and-permit block
Default 0 0
Timeout 0 0
Connectivity 0 0
Too-many-requests 0 0
That’s pretty much all there is to it for a basic EWF setup. There are many more nerdknobs you can tune but I’ll stick to the basics for my JNCIP-SEC studies.
Bear in mind that the URL filter only works for HTTP traffic and most of the web these day is on SSL and using CDN networks, so it’s very hard to get a good match on SSL traffic. This can be solved by using SSL Forward Proxy or relying more on Layer-7 AppID with custom application signatures.
Sources: