In this post I will go through the basics of cluster configuration on the SRX. I still have a couple of SRX100s laying around, which is perfect to cover the clustering topics of the JNCIS-SEC blueprint!
Before you start configuring the cluster, always verify that both your boxes are on the same software version.
root@FW01A> show system software Information for junos: Comment: JUNOS Software Release [12.1X44-D40.2]
Physical Wiring
Here is how the cluster will be cabled up. Because there’s a lot to remember during the configuration, it’s best to make this sort of diagram before you begin.
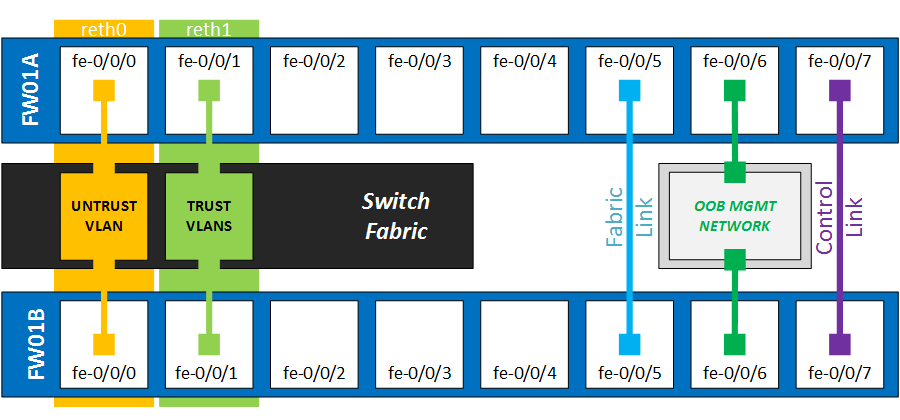
Connect the fxp1 and Fab ports
The Control link (fxp1) is used to synchronize configuration and performs cluster health checks by sending heartbeat messages. The physical port location depends on the SRX model, and can also be configurable on the high-end models. In my case, on the branch SRX100B, the fe0/0/07 interfaces are predetermined as fxp1.
The fab interface is used to exchange all the session state information between both devices. This provides a stateful failover if anything happens to the primary cluster node. You can choose which interface to assign. I will use fe/0/0/5 so all the first ports stay available.
Setting the Cluster-ID and Node ID
First, wipe all the old configuration and put both devices in cluster mode. Some terminology:
- The cluster ID ranges from 1 to 15 and uniquely identifies the cluster if you have multiple clusters across the network. I will use Cluster ID 1
- The node ID identifies both members in the cluster. A cluster will only have two members ever, so the options are 0 and 1
The commands below are entered in operational mode:
root@FW01A> set chassis cluster cluster-id 1 node 0 reboot Successfully enabled chassis cluster. Going to reboot now
root@FW01B> set chassis cluster cluster-id 1 node 1 reboot Successfully enabled chassis cluster. Going to reboot now
Keep attention when you enter the commands above. Make sure you are actually enabling the cluster, not disabling it. That would return the following message:
Successfully disabled chassis cluster. Going to reboot now
Configuring the management interfaces
Once the devices have restarted we can move on to the configuration part.
To get out-of-band access to your firewalls, you really should configure both the members with a managment IP on the fxp0 interface.
All member-specific configuration is applied under the groups node-memmbers stanza. This is also where the hostnames are configured.
{primary:node0}[edit groups]
root@FW01A# show
node0 {
system {
host-name FW01A;
}
interfaces {
fxp0 {
unit 0 {
family inet {
address 192.168.1.1/24;
}
}
}
}
}
node1 {
system {
host-name FW01B;
}
interfaces {
fxp0 {
unit 0 {
family inet {
address 192.168.1.2/24;
}
}
}
}
}
On the SRX100B, the fxp0 interface is automatically mapped to the fe0/0/6 interface. Be sure to check the documentation for your specific model.
Apply Group
Before committing, don’t forget to include the command below . This ensures that node-specific config is only applied to that particular node.
{primary:node0}[edit]
root@FW01A# set apply-groups "${node}"
Configuring the fabric interface
The next step is to configure your fabric links, which are used to exchange the session state. Node0 has the fab0 interface and Node1 has the fab1 interface.
{primary:node0}[edit interfaces]
root@FW01A# show
fab0 {
fabric-options {
member-interfaces {
fe-0/0/5;
}
}
}
fab1 {
fabric-options {
member-interfaces {
fe-1/0/5;
}
}
}
After a commit, we can see both the control and fabric links are up.
root@FW01A# run show chassis cluster interfaces
Control link status: Up
Control interfaces:
Index Interface Status
0 fxp1 Up
Fabric link status: Up
Fabric interfaces:
Name Child-interface Status
(Physical/Monitored)
fab0 fe-0/0/5 Up / Up
fab0
fab1 fe-1/0/5 Up / Up
fab1
Redundant-pseudo-interface Information:
Name Status Redundancy-group
lo0 Up 0
Configuring the Redundancy Groups
The redundancy group is where you configure the cluster’s failover properties relating to a collection of interfaces or other objects. RG0 is configured by default when you activate the cluster, and manages the redundancy for the routing engines. Let’s create a new RG 1 for our interfaces.
{secondary:node0}[edit chassis]
root@FW01A# show
cluster {
redundancy-group 0 {
node 0 priority 100;
node 1 priority 1;
}
redundancy-group 1 {
node 0 priority 100;
node 1 priority 1;
}
}
Configuring Redundant Ethernet interfaces
The reth interfaces are bundles of physical ports across both cluster members. The child interfaces inherit the configuration from the overlying reth interface – think of it as being similar to an 802.3ad Etherchannel. In fact, you can use an Etherchannel to use more than one physical port on each node.
{secondary:node0}[edit chassis cluster]
root@FW01A# set reth-count 2
After entering this command, you can do a quick commit, which will make the reth interfaces visible in the terse command.
root@FW01A# run show interfaces terse | match reth reth0 up down reth1 up down
Now you can configure the reth interfaces as you would with any other interface, give them an IP and assign them to the Redundancy Group.
reth0 is our outside interface, and reth1 is the inside.
{secondary:node0}[edit interfaces]
root@FW01A# show reth0
redundant-ether-options {
redundancy-group 1;
}
unit 0 {
family inet {
address 1.1.1.1/24;
}
}
{secondary:node0}[edit interfaces]
root@FW01A# show reth1
redundant-ether-options {
redundancy-group 1;
}
unit 0 {
family inet {
address 10.0.0.1/24;
}
}
When our reths are configured, we can add our physical ports. The fe-0/0/0 (node0) and fe-1/0/0 (node1) will join reth0, fe-0/0/1 and fe-1/0/1 will join reth1.
{secondary:node0}[edit interfaces]
root@FW01A# show
fe-0/0/0 {
fastether-options {
redundant-parent reth0;
}
}
fe-0/0/1 {
fastether-options {
redundant-parent reth1;
}
}
fe-1/0/0 {
fastether-options {
redundant-parent reth0;
}
}
fe-1/0/1 {
fastether-options {
redundant-parent reth1;
}
}
Interface monitoring
We can use interface monitoring to subtract a predetermined priority value off our redundancy group priority, when a link goes physically down.
For example, node0 is primary for RG1 with a priority of 100. If we add an interface-monitor value of anything higher than 100 to the physical interface, the link-down event will cause to priority to drop to zero and trigger the failover. Configuration is applied at the redundancy-groups:
{primary:node0}[edit chassis cluster]
root@FW01A# show
reth-count 2;
redundancy-group 0 {
node 0 priority 100;
node 1 priority 1;
}
redundancy-group 1 {
node 0 priority 100;
node 1 priority 1;
preempt;
gratuitous-arp-count 5;
interface-monitor {
fe-0/0/0 weight 255;
fe-0/0/1 weight 255;
fe-1/0/0 weight 255;
fe-1/0/1 weight 255;
}
}
Finally, we add the interfaces to security zones.
root@FW01A# show security zones
security-zone untrust {
interfaces {
reth0.0;
}
}
security-zone trust {
host-inbound-traffic {
system-services {
ping;
}
}
interfaces {
reth1.0;
}
}
Verification
After cabling it up, we can verify that the cluster is fully operational.
root@FW01A> show chassis cluster status
Cluster ID: 1
Node Priority Status Preempt Manual failover
Redundancy group: 0 , Failover count: 0
node0 100 primary no no
node1 1 secondary no no
Redundancy group: 1 , Failover count: 0
node0 100 primary yes no
node1 1 secondary yes no
root@FW01A> show chassis cluster interfaces
Control link status: Up
Control interfaces:
Index Interface Status
0 fxp1 Up
Fabric link status: Up
Fabric interfaces:
Name Child-interface Status
(Physical/Monitored)
fab0 fe-0/0/5 Up / Up
fab0
fab1 fe-1/0/5 Up / Up
fab1
Redundant-ethernet Information:
Name Status Redundancy-group
reth0 Up 1
reth1 Up 1
Redundant-pseudo-interface Information:
Name Status Redundancy-group
lo0 Up 0
Interface Monitoring:
Interface Weight Status Redundancy-group
fe-1/0/1 255 Up 1
fe-1/0/0 255 Up 1
fe-0/0/1 255 Up 1
fe-0/0/0 255 Up 1
Let’s see how long the failover takes, by unplugging one of the links in the trust zone.
Pinging from the inside switch to the reth1 address 10.0.0.1
theswitch#ping 10.0.0.1 repeat 10000 Type escape sequence to abort. Sending 10000, 100-byte ICMP Echos to 10.0.0.1, timeout is 2 seconds: !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!.!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Excellent, only lost one ping while failing over to node1 which would be 2 seconds.
We can see that node1 is now the primary for redundancy group 1, which holds our interfaces:
root@FW01A> show chassis cluster status redundancy-group 1
Cluster ID: 1
Node Priority Status Preempt Manual failover
Redundancy group: 1 , Failover count: 3
node0 0 secondary yes no
node1 1 primary yes no
{primary:node0}
In the next article, I will dive a bit deeper and integrate the SRX cluster in a real-world topology.